Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
“Якутский государственный университет им. М.К. Аммосова”
Технический институт (филиал) в г. Нерюнгри
Педагогический факультет
Кафедра Математики и Информатики
КУРСОВАЯ РАБОТА
по дисциплине «Теория вероятностей и математическая статистика»
на тему: «Дисперсионный анализ показателей смертностей населения Нерюнгринского улуса»
Студентка:
Копотева К. Г., гр. ПМ-04
Руководитель:
Преподаватель:
доцент кафедры к.ф.–м.н.
Попова А.М.
Оценка курсовой работы:__________________
Принял:_______________ Дата _____________
Нерюнгри 2007
Содержание
Введение
1. Теоретическая часть
1.1. Однофакторный дисперсионный анализ
1.2. Линейный множественный регрессионный анализ
1.3. Множественный корреляционный анализ
2. Аналитическая часть
2.1. Сбор и первичная обработка данных
2.2. Дисперсионный анализ
2.3. Построение уравнения множественной регрессии
2.4. Исключение незначимых факторов
3. Заключение
4. Список литературы
5. Приложение
Введение
Анализируя данные, о смертности населения за 2004-2006 год, полученные в Нерюнгринской городской больнице (см. таблицу 1), можно сделать вывод о том, что общий коэффициент смертности, то есть число умерших от всех причин на 1000 человек населения, увеличивается (рис.1).
Показатель смертности на 1000 человек населения
Таблица 1
| 2004 год | 2005 год | 2006 год |
| 7.3 | 7.8 | 8.1 |
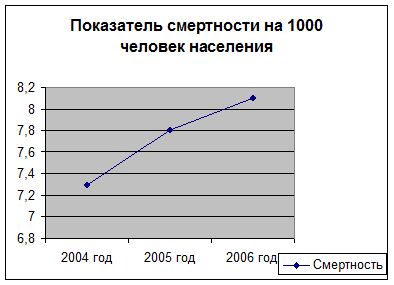
Рисунок 1
Несмотря на повышение рождаемости, демографическая ситуация в Нерюнгринском улусе характеризуется уменьшением численности населения. Главной причиной демографического кризиса является преобладание смертности над рождаемостью. Именно поэтому, чтобы снизить показатель смертности необходимо более детально изучить все причины и факторы, приводящие к ее увеличению. Несомненно, в изучении причин, важно исследование значимости отдельных нозологических форм заболеваний. Зная, какие заболевания приводят чаще всего к летальному исходу, можно разработать программу профилактических работ направленную на уменьшение числа данных заболеваний и предотвращения их дальнейшего развития на раннем этапе.
Цель: определение видов заболеваний оказывающих наибольшее влияние на показатели летальности, основываясь на статистике смертности населения Нерюнгринского улуса по классам болезней и возрастам за 2006 год.
Задачи:
1. сбор статистических данных необходимых для определения закономерности изменения смертности по причинам заболеваний;
2. проведение однофакторного дисперсионного анализа, с целью определения влияния различных болезней на общее количество смертности населения;
3. исключение отдельных факторов, оказывающих незначительное влияние;
4. построение уравнения множественной регрессии, отражающего соотношение между смертностью и различными классами заболеваний.
1. Теоретическая часть
1.1. Однофакторный дисперсионный анализ
Дисперсионный анализ (от латинского Dispersio - рассеивание) - статистический метод, позволяющий анализировать влияние различных факторов на исследуемую переменную. Метод был разработан биологом Р. Фишером в 1925 году и применялся первоначально для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Целью дисперсионного анализа является проверка значимости различия между средними с помощью сравнения дисперсий. Дисперсию измеряемого признака разлагают на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации.
Пусть генеральные совокупности Х 1 , Х 2 ,…, Хр распределены нормально и имеют одинаковую, хотя и неизвестную дисперсию. Математические ожидания которых известны и могут быть различны при заданном уровне значимости α. Проверим при заданном уровне значимости нулевую гипотезу Н 0 : М (Х 1 ) = М (Х 2 ) = … = М (Хр ) о равенстве всех математических ожиданий. Это означает, что мы устанавливаем значимо или нет, различаются выборочные средние.
На практике дисперсионный анализ применяют, чтобы установить оказывает ли существенное влияние качественный фактор F , имеющий p уровней: F 1 , F 2 , …, Fp , на изучаемую величину.
Основная идея дисперсионного анализа состоит в сравнение «факторной дисперсии», то есть рассеяние, порождаемое изменением уровня фактора, и «остаточной дисперсии», обусловленной случайными причинами. Если их различие значимо, то фактор существенно влияет на Х и при изменении его уровня групповые средние различаются значимо. Если установили, что фактор существенно влияет на Х, а требуется выяснить, какой из уровней оказывает наибольшее воздействие, то дополнительно производим попарное сравнение средних. Дисперсионный анализ также применяется для установления однородности нескольких совокупностей (если математические ожидания одинаковы, то совокупности однородны). В более сложных случаях исследуют воздействие нескольких факторов на различные постоянные или различные уровни и выясняют влияние отдельных уровней и их комбинацию (многоуровневый анализ).
Будем считать, что количество наблюдений на каждом уровне фактора одинаково и равно q . Оформим результаты наблюдений в виде таблицы:
Номер испытания |
Уровни фактора Fj | |||
| F 1 | F 2 | … | Fp | |
1 2 … q |
x 11 x 21 … xq 1 |
x 12 x 22 … xq 2 |
… … … … |
x 1p x 2p … xqp |
Групповое среднее |
… | |||
Сумму квадратов отклонения можно определить по формулам:
1. Общая сумма квадратов отклонений наблюдаемых значений от общего среднего ![]() [1]:
[1]:
![]() . (1)
. (1)
![]() характеризует влияние фактора F и случайных причин на Х.
характеризует влияние фактора F и случайных причин на Х.
2. Факторная сумма отклонений групповых средних от общей средней, характеризующая рассеяние между группами [1]:
![]() . (2)
. (2)
![]() характеризует воздействие фактора F на величину Х.
характеризует воздействие фактора F на величину Х.
Остаточная сумма квадратов отклонений наблюдаемых значений группы от своего группового среднего, характеризующая рассеяние внутри групп [1]:
![]() . (3)
. (3)
![]()
![]() отображает влияние случайных причин на Х.
отображает влияние случайных причин на Х.
Вводя обозначения [1]:
![]() , (4)
, (4)
получим формулы, более удобные для расчетов [1]:
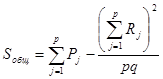 , (5)
, (5)
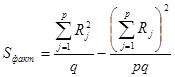 . (6)
. (6)
Разделив суммы квадратов на соответствующее число степеней свободы, получим общую, факторную и остаточную дисперсии [1]:
![]() . (7)
. (7)
Если справедлива гипотеза Н 0 , то все эти дисперсии являются несмещенными оценками генеральной дисперсии.
Вычисляем ![]() и сравниваем с F
кр
(критерий Фишера - Снедекора) [1]:
и сравниваем с F
кр
(критерий Фишера - Снедекора) [1]:
F кр (α; n-1; nk-(k-1)),
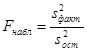 , (8)
, (8)
где α – уровень значимости; n – количество факторов; k – количество испытаний.
Если F набл <F кр , то гипотеза о равенстве дисперсий будет принята.
Если число испытаний на разных уровнях различно (q 1 испытаний на уровне F 1 , q 2 – на уровне F 2 , …, qр - на уровнеF р ), то [1]:
![]() , (9)
, (9)
где ![]() сумма квадратов наблюдавшихся значений признака на уровне Fj
,
сумма квадратов наблюдавшихся значений признака на уровне Fj
,
![]() сумма наблюдавшихся значений признака на уровне Fj
.
сумма наблюдавшихся значений признака на уровне Fj
.
При этом объем выборки, или общее число испытаний, равен ![]() . Факторная сумма квадратов отклонений вычисляется по формуле [1]:
. Факторная сумма квадратов отклонений вычисляется по формуле [1]:
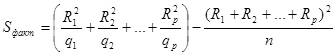 . (10)
. (10)
Остальные вычисления проводятся так же, как в случае одинакового числа испытаний [1]:
![]() . (11)
. (11)
1.2. Линейный множественный регрессионный анализ
Регрессионный анализ, по-видимому, наиболее широко используемый метод многомерного статистического анализа. Термин ''множественная регрессия'' объясняется тем, что анализу подвергается зависимость одного признака (результирующего) от набора независимых (факторных) признаков. Разделение признаков на результирующий и факторные осуществляется исследователем на основе содержательных представлений об изучаемом явлении (процессе). Все признаки должны быть количественными (хотя допускается и использование дихотомических признаков, принимающих лишь два значения, например 0 и 1).При поведении экспериментов в множественной ситуации исследователь записывает показания приборов о состоянии функции отклика (y) и всех факторов, от которых она зависит (xi ).
При построении регрессионных моделей, прежде всего, возникает вопрос о виде функциональной зависимости, характеризующей взаимосвязи между результирующим признаком и несколькими признаками-факторами. Выбор формы связи должен основываться на качественном, теоретическом и логическом анализе сущности изучаемых явлений. Чаще всего ограничиваются линейной регрессией, т.е. зависимостью вида [2]:
Y=a0 +a1 x1 +a2 x2 +…+an xn (12)
где Y - результирующий признак; x1 , …, xn - факторные признаки; a1 ,…,an - коэффициенты регрессии; а0 - свободный член уравнения. ai находим методом наименьших квадратов, для этого рассматривается функции [2]:
![]() (13)
(13)
Находим частные производные по неизвестным переменным, приравниваем к нулю и получаем систему уравнений. Решая систему, можем найти наименьшее значение функции.
Так как запись множественной регрессии (линейной) в матричной форме имеет вид [2]:
Y=X*A, (14)
где Y - это вектор-столбец опытных значений изучаемой характеристики; X –матрица всех значений всех рассматриваемых факторов, полученных при проведении измерений или наблюдений; А – вектор-столбец искомых коэффициентов аппроксимирующего полинома (12) [2]:
Y=![]() ; (15)
; (15)
X=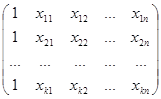 ; (16)
; (16)
Y=![]() ; (17)
; (17)
Тогда функционал F метода наименьших квадратов имеет вид [2]:
![]() (18)
(18)
Для оценки адекватности рассчитанной регрессионной модели вычисляется коэффициент детерминации, он показывает, какая часть дисперсии функции отклика объясняется вариацией линейной комбинации выбранных факторов x1 , x2 ,…, xj , xn [2]:
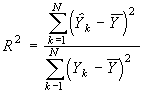 , (19)
, (19)
где ![]() - прогнозные значения
- прогнозные значения
и множественный коэффициент корреляции [2]:
![]() . (20)
. (20)
Значение коэффициента множественной корреляции оценивается с помощью таблицы 2 [1]:
Таблица Чеддока Таблица 2
| диапазон измерения | характер тесноты |
| слабая | |
| умеренная | |
| заметная | |
| высокая | |
| весьма высокая |
1.3. Множественный корреляционный анализ
Расчеты обычно начинают с вычисления парных коэффициентов корреляции, характеризующих тесноту связи между двумя величинами. В множественной ситуации вычисляют два типа парных коэффициентов корреляции:
1. ![]() - коэффициенты, определяющие тесноту связи между функцией отклика y и одним из факторов
- коэффициенты, определяющие тесноту связи между функцией отклика y и одним из факторов ![]() [2]:
[2]:
![]()
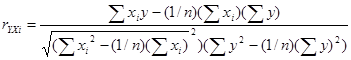 . (21)
. (21)
2. ![]() - коэффициенты, показывающие тесноту связи между одним из факторов xi
и фактором xm
(i, m=
- коэффициенты, показывающие тесноту связи между одним из факторов xi
и фактором xm
(i, m=![]() ) [2]:
) [2]:
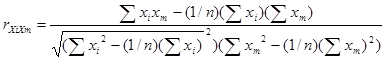 (22)
(22)
.
Значение парного коэффициента изменяется, как указывалось выше, изменяется от -1 до +1. Если, например, коэффициент ![]() - величина отрицательная, то это значит, что xi
уменьшается с увеличением y. Если
- величина отрицательная, то это значит, что xi
уменьшается с увеличением y. Если ![]() положителен, то xi
увеличивается с увеличением y.
положителен, то xi
увеличивается с увеличением y.
Значимость парных коэффициентов корреляции можно проверить двумя способами:
1)сравнение с табличным значениями ![]() [2]:
[2]:
![]() , (23)
, (23)
2) по t-критерию Стьюдента [2]:
![]() , (24)
, (24)
Где ![]() - среднеквадратическая погрешность выборочного парного коэффициента корреляции [2]:
- среднеквадратическая погрешность выборочного парного коэффициента корреляции [2]:
![]() . (25)
. (25)
Здесь ![]() определяется по таблице с числом степеней свободы
определяется по таблице с числом степеней свободы ![]() .
.
Доверительный интервал для парных коэффициентов корреляции [2]:
![]() , (26)
, (26)
где ![]() - парный коэффициент корреляции в генеральной совокупности.
- парный коэффициент корреляции в генеральной совокупности.
Если один из коэффициентов ![]() окажется равным 1, то это означает, что факторы xi
и xm
функционально (не вероятностно) связаны между собой и тогда целесообразно один из них исключить из рассмотрения, причем оставляют тот фактор, у которого коэффициент
окажется равным 1, то это означает, что факторы xi
и xm
функционально (не вероятностно) связаны между собой и тогда целесообразно один из них исключить из рассмотрения, причем оставляют тот фактор, у которого коэффициент ![]() больше.
больше.
После вычисления всех парных коэффициентов корреляции и исключения из рассмотрения того или иного фактора можно построить матрицу коэффициентов корреляции вида [2]:
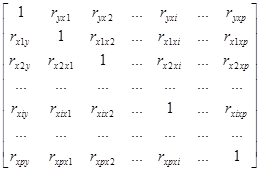 . (27)
. (27)
Используя матрицу (23) можно вычислить частные коэффициенты, которые показывают степень влияния одного из факторов xi на функцию отклика y при условии, что все остальные факторы закреплены на постоянном уровне. Формула для вычисления частных коэффициентов корреляции такова [2]:
![]() , (28)
, (28)
где ![]() - определитель матрицы, образованной из матрицы (27) вычеркиванием 1-й строки, i-го столбца. Определители
- определитель матрицы, образованной из матрицы (27) вычеркиванием 1-й строки, i-го столбца. Определители ![]() ,
, ![]() вычисляются аналогично. Как и парные коэффициенты, частные коэффициенты корреляции изменяются от -1 до +1.
вычисляются аналогично. Как и парные коэффициенты, частные коэффициенты корреляции изменяются от -1 до +1.
2. Аналитическая часть
2.1. Сбор и первичная обработка данных
В ходе сбора материалов исследования, определенных выбранной темой, были получены статистические данные по динамике смертности всего населения Нерюнгринского улуса по классам болезней и возрастам. Классы заболеваний, в исходных данных имеют следующую классификацию:
I. Некоторые инфекционные и паразитарные заболевания;
II. Новообразования;
III. Болезни крови, кроветворных органов и отдельные нарушения, вовлекшие иммунный механизм;
IV. Болезни эндокринной системы, расстройства питания и нарушения обмена веществ;
V. Психические расстройства и расстройства поведения;
VI. Болезни нервной системы;
VII. Болезни глаза и его придаточного аппарата;
VIII. Болезни уха и сосцевидного отростка;
IX. Болезни системы кровообращения;
X. Болезни органов дыхания;
XI. Болезни органов пищеварения;
XII. Болезни кожи и подкожной клетчатки;
XIII. Болезни костно–мышечной системы и соединительной ткани;
XIV. Болезни мочеполовой системы;
XV. Беременность, роды и послеродовый период;
XVI. Отдельные состояния, возникающие в перинатальном периоде;
XVII. Врожденные аномалии (пороки развития), деформации и хромосомные нарушения;
XVIII. Симптомы, признаки и отклонения от нормы, выявленные при клинических и лабораторных исследованиях, не классифицированные в других рубриках;
XIX. Травмы, отравления и некоторые другие последствия воздействия внешних причин;
XX. Внешние причины заболеваемости и смертности.
После обработки этих данных была получена таблица 1 [см. Приложение], в которой представлено количественное изменение смертности по причинам различных заболеваний. В эту таблицу вошли следующие классы болезней: некоторые инфекционные и паразитарные заболевания, новообразования, болезни эндокринной системы, расстройства питания и нарушения обмена веществ, психические расстройства и расстройства поведения, болезни нервной системы, болезни системы кровообращения, болезни органов дыхания, болезни органов пищеварения, болезни костно–мышечной системы и соединительной ткани, болезни мочеполовой системы, беременность, роды и послеродовый период, врожденные аномалии (пороки развития), деформации и хромосомные нарушения, симптомы, признаки и отклонения от нормы, выявленные при клинических и лабораторных исследованиях, не классифицированные в других рубриках, травмы, отравления и некоторые другие последствия воздействия внешних причин, внешние причины заболеваемости и смертности.
Таким образом, функцией отклика является смертность населения в конкретной возрастной группе, а факторами, влияющими на ее изменение, являются классы заболеваний.
2.2. Дисперсионный анализ
Методом дисперсионного анализа, выясним, оказывает ли влияние различные заболевания на показатель смертности населения. То есть, проверим, выполняется ли гипотеза о равенстве математических ожиданий (Н
0
: М
(Х
1
) = М
(Х
2
) = … = М
(Хр
)). Для этого рассчитаем значения наблюдавшихся признаков ![]() и значения их квадратов
и значения их квадратов ![]() для каждого заболевания по формуле (4). Затем, вычислив их сумму, результаты вычислений приведены в таблице 2 [см. Приложение]. Подставим в формулы (5), (6), получим значения общей и факторной дисперсий:
для каждого заболевания по формуле (4). Затем, вычислив их сумму, результаты вычислений приведены в таблице 2 [см. Приложение]. Подставим в формулы (5), (6), получим значения общей и факторной дисперсий:
![]() 13498;
13498;
![]() 5906,7;
5906,7;
Эти значения подставляем в формулу (11) вычисляем остаточную сумму квадратов отклонений наблюдаемых значений группы от своего группового среднего.
![]() 7591,5
7591,5
Теперь мы можем вычислить F набл , для этого используем формулу (8), и сравниваем с F кр , который, смотрится по таблице критерия Фишера – Снедекора [1].
F набл =14, 1090;
F кр (0,01; 15; 18)= 3,23.
Сравнивая полученные значения, мы делаем вывод о том, что различия между дисперсиями не значимо, то есть фактор (заболевания) оказывает существенное влияние на функцию отклика (смертность). Следовательно, среднее наблюдаемое значение на каждом уровне (групповые средние) различаются значимо.
2.3. Построение уравнения множественной регрессии
Следующим этапом, мы построим уравнение множественной регрессии. Для этого мы воспользовались Пакетом анализа данных для вычисления основных статистических параметров выборки. Для того чтобы отыскать команду вызова надстройки Пакет анализа в MicrosoftExcel, необходимо воспользоваться меню Сервис – Анализ данных.… В появившемся диалоговом окне выбрать пункт Регрессия. В поле Входной интервал Y: указать диапазон значений нашего у, в поле Входной интервал X: указать все значения наших x. В разделе параметры вывода указать Выходной интервал: ввести любую, удобную для вас ячейку. Результаты работы режима Регрессия представлен в таблице 3 [см. Приложение]. Таким образом, наше уравнение регрессии имеет вид:
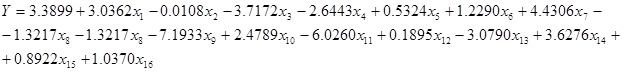
2.4. Исключение незначимых факторов
Для того чтобы исключить заболевания, которые оказывают незначительное влияние на смертность население, вначале рассчитаем парные коэффициенты корреляции по формулам (21), (22), и построим корреляционную матрицу (см. таблицу 4 [Приложение]). Используя полученную матрицу, вычислим по формуле (28) частные коэффициенты корреляции, получим:
| Ryx1 | 0,012345 | Ryx9 | -0,85883735 |
| Ryx2 | 0,79942633 | Ryx10 | -0,9606058 |
| Ryx3 | 0,01902545 | Ryx11 | -0,66239756 |
| Ryx4 | -0,7279617 | Ryx12 | -0,81452592 |
| Ryx5 | 0,25701348 | Ryx13 | -0,16934424 |
| Ryx6 | 0,30479306 | Ryx14 | 0,9030776 |
| Ryx7 | -0,9799582 | Ryx15 | 0,10681524 |
| Ryx8 | 0,96909722 | Ryx16 | 0,97533032 |
Сравнивая частные коэффициенты корреляции и парные коэффициенты, исключаем незначительные факторы. Факторы, которые после сравнения этих коэффициентов оказались незначимы, можно исключить из уравнения регрессии. В уравнение регрессии, которое мы получили, таковыми оказались x1 , x3 , x4 , x9 , x10 , x11 , x12 , x13 и x16 . То есть инфекционные и паразитарные заболевания, болезни эндокринной системы, расстройства питания и нарушения обмена веществ, психические расстройства и расстройства поведения, болезни костно–мышечной системы и соединительной ткани, болезни мочеполовой системы, беременность, роды и послеродовый период, врожденные аномалии (пороки развития), отравления и некоторые другие последствия воздействия внешних причин, отдельные состояния, возникающие в перинатальном периоде не оказывают существенного влияния на смертность.
Так как мы исключили некоторые факторы, уравнение регрессии изменилось, поэтому необходимо вновь, воспользовавшись Пакетом Анализ данных, построить новое уравнение регрессии (см. таблицу 5 [Приложение]). Теперь уравнение представимо в виде:
![]()
Данное уравнение отображает функциональную связь между смертностью и различными классами заболеваний.
Заключение
В данной курсовой работе рассмотрены заболевания, влияющие на изменение смертности Нерюнгринского улуса. Были выбраны факторы, методом исключения эффектов, приводящие к высокой смертности. Применяя методы теории вероятностей и математической статистики, было построено уравнение, показывающее зависимость изучаемого явления (смертности) от выбранных факторов (классов заболеваний).
Проведя анализ полученной модели, выяснилось, что наиболее часто приводят к летальному исходу болезни
8-09-2015, 13:28