Связность является одним из важных свойств текстовой информации. Любая информация представляет собой набор тех или иных фактов, причем часть из них непременно связана между собой. Очевидно, что при передаче этой информации в текстовом виде необходимо найти способ сохранить связи. Если этого не сделать, то мы не получим адекватного представления о внешней среде, а только отдельные ее фрагменты, не дающие целостной картины. Каким же образом реализуется связность?
Самым очевидным и логичным способом реализации связности текстовой информации представляется повтор. Суть его состоит в следующем: если предложение А связано с предложением Б, то эти два предложения содержат некоторую одинаковую часть, повторяющуюся информацию, которая и показывает наличие связи между А и Б. Таким образом, приходится жертвовать одним из важнейших принципов организации языкового материала - отсутствием избыточности, но эта жертва необходима для корректной передачи информации о внешней среде.
Далее будем исходить из того, что связность текста сохраняется в пределах одного абзаца.
Чтобы сделать возможным выявление связей, каждое предложение абзаца разбивается на две части: координаты и собственно информацию. Координаты - та самая общая часть, служащая для связи с другими предложениями. Остальная часть содержит уникальную, новую информацию, для передачи которой и служит в тексте это предложение. Существует три типа связности, различающиеся схемами построения координатных зависимостей:
| Kn |
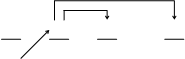
1. ![]() Описание «вглубь» (1). В этом случае связность реализуется последовательной цепочкой, то есть предложение 1 связано с 2, 2 с 3 и т. д.
Описание «вглубь» (1). В этом случае связность реализуется последовательной цепочкой, то есть предложение 1 связано с 2, 2 с 3 и т. д.
| K1 |
| K2 |
| K3 |
2. Описание «вширь» (2). В этом случае связность реализуется по параллельному принципу, когда все предложения 2, 3 и т. д. связаны с предложением 1.
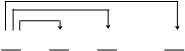 |
К1 |
| К2 |
| К3 |
| Кn |
| К1 |
| Кn |
3. Комбинированная схема (3). Представляет собой смешанный вариант 1 и 2.
| К2 |
| К3 |
 |
Лингвистический процессор может решать две задачи, имеющие отношение к связности:
· Задача анализа. В этом случае целью является выявление всех связей между предложениями некоторого текста.
· Задача синтеза. Цель этой задачи - построение текста, описывающего некоторый фрагмент внешней среды с сохранением связей между объектами.
Далее будет рассмотрен алгоритм решения задачи анализа.
Перед тем как описывать алгоритм программной реализации задачи анализа, необходимо сделать одно замечание. Для качественного решения задачи требуется наличие достаточно обширной базы данных, в которой хранились бы сведения о различных морфологических представлениях слов, а также, для еще более полной картины, соответствия между словами-синонимами. В данной работе задача реализации такой базы данных не рассматривается. Описываемый алгоритм определяет связи в тексте только путем поиска повторяющихся слов.
Работа алгоритма происходит в следующей последовательности:
1. Предварительный анализ текста с целью разбиения его на отдельные предложения. Предложение считается законченным, как только обнаружена точка, причем за точкой следует либо большая буква, либо ничего, если конец предложения одновременно является концом текста.
2. Анализ предложений с целью выделения отдельных слов. Предполагается, что слова разделяются пробелами или другими символами-разделителями.
3. Создание двумерного массива, в котором одна координата определяет порядковый номер предложения, а другая - порядковый номер слова в этом предложении.
4. Поиск связей для каждого слова текста. Этот поиск происходит в цикле и состоит из таких этапов:
a) чтение следующего слова и его проверка. Слова длиной меньше трех символов не анализируются, чтобы исключить ошибочные связи по союзам, предлогам и т.п.;
b) поиск в тексте слов, у которых совпадает с данным словом не менее 3 первых символов и не менее 3/4 от его длины. Таким образом учитывается возможность наличия у повторяющихся слов разных окончаний. Можно также ограничивать глубину поиска, т. е. количество предложений после текущего, в которых необходимо искать связи. Если производить поиск только в одном следующем предложении, то будут найдены только связи по схеме (1);
c) запоминание координат найденных связей в массиве. При этом создается таблица, в которой вводится запись для каждого набора координат. Если работать только по схеме (1), то эти записи будут представлять собой пары.
5. По окончании цикла может быть построена схема, демонстрирующая все связи в тексте.
6. Возможно также произвести разбиение текста на абзацы: началом нового абзаца считается предложение, в котором нет ни одной связи с каким-либо из слов предыдущей части текста.
Алгоритм не дает гарантии правильности полученного результата. В частности, возможны следующие ошибки:
· нахождение несуществующих связей по вспомогательным частям речи;
· нахождение несуществующих связей по сходным в написании, но не однокоренным словам;
· потеря связей по коротким словам.
Избежать этих ошибок можно, как уже говорилось, только при дополнении программы базой данных.
29-04-2015, 02:40