Леонид Соломонович Файнзильберг
Развивается подход к построению схемы принятия коллективного решения в условиях противоречивой информации, полученной от независимых экспертов. Показано, что только при равновероятных классах групповое решение должно совпадать с частным решением более квалифицированного эксперта. Предложены правила, обеспечивающие минимизацию средней вероятности ошибки коллективного решения.
Введение.
Различные сферы профессиональной деятельности человека связаны с принятием решений, которые сводятся к выбору оптимального варианта поведения из множества альтернатив [1,2]. Довольно часто такой выбор опирается на информацию, которую лицо, принимающее решение, получает в виде рекомендаций от коллектива экспертов [3-7].
Целый ряд прикладных задач, например, задач медицинской и технической диагностики, также сводится к принятию решения: необходимо определить принадлежность состояния объекта исследования к одному из нескольких заранее определенных классов (диагнозов) [8]. В простейших случаях достаточно сделать выбор между двумя возможными состояниями, например “болен” - “здоров”, “исправен - неисправен”. В других случаях число возможных диагнозов больше двух.
При решении таких задач используются методы распознавания образов, позволяющие автоматизировать процесс диагностики. С этой целью состояние объекта описывается совокупностью некоторых параметров (признаков) и строится алгоритм распознавания, который после соответствующей настройки (обучения) обеспечивает классификацию текущего состояния объекта. Обычно эффективность таких систем оценивается вероятностью ошибочной классификации.
Для повышения эффективности систем распознавания в последнее время внимание специалистов привлекают так называемые коллективные (комбинированные) классификаторы [9,10]. Их суть состоит в том, что окончательное решение принимается на основе “интеграции” частных решений, которые принимают отдельные классификаторы.
Существуют различные подходы к интеграции частных решений. В одних случаях предлагается использовать метод голосования (majority vote method) [11,12] или ранжирования (label ranking method) [13, 14]. В других - использовать схемы, основанные на усреднении или линейной комбинации апостериорных вероятностей, которые оцениваются отдельными классификаторами [15,16], либо использовать алгоритмы нечетких правил (fuzzy rules) [17]. Предлагается также проводить независимое обучение комбинированного классификатора, рассматривая частные решения как новые комплексные признаки [18,19]. Развиваются также подходы, основанные на выделении в пространстве наблюдений локальных областей, в каждой из которых только один из частных классификаторов “компетентен” принимать решение [20].
Все эти работы имеют несомненный теоретический интерес и, как показано в [21], позволяют обосновать выбор той или иной схемы интеграции, если известны алгоритмы принятия частных решений и характеристики признаков, которые используют отдельные классификаторы.
В то же время на практике, как отмечено в [1], приходится принимать решения и в тех случаях, когда рассматриваемая проблема слабо структурирована, а формализации поддаются лишь отдельные фрагменты общей постановки. Довольно часто эксперты при анализе ситуаций используют не количественные, а качественные признаки [22], а сами решения принимают на основе эвристических алгоритмов либо просто полагаются на свой предшествующий опыт и интуицию.
Разумеется в этих практически важных случаях также требуется обоснованный подход к интеграции частных решений экспертов. Например, какое окончательное решение должно быть принято, если в результате независимого обследования часть специалистов (экспертов) признала пациента здоровым, а другая часть – больным?
Можно привести и другие не менее актуальные примеры необходимости принятия коллективных решений в условиях противоречий при ограниченной априорной информации о частных решениях экспертов.
В настоящей статье развивается один из возможных подходов к решению таких задач.
Постановка задачи.
Пусть некоторый объект Z находится в одном из М возможных состояний (классов) V1 ,...,VM с известными априорными вероятностями P(V1),...,P(VM),![]() . Ясно, что если не располагать какой либо дополнительной информацией, то состояние Z всегда следует относить к классу, имеющему наибольшую априорную вероятность. В этом случае величина
. Ясно, что если не располагать какой либо дополнительной информацией, то состояние Z всегда следует относить к классу, имеющему наибольшую априорную вероятность. В этом случае величина
P0 =1- max{P(V1),...,P(VM)}, (1)
определяет минимальную вероятность ошибочной классификации.
Предположим теперь, что имеется N экспертов (алгоритмов) A1,…, AN, которые на основании дополнительной информации независимо один от другого принимают решения δi(Z) о состоянии объекта Z в виде индикаторных функций
δi(Z) = k, если Ai решает в пользу Vk, i =1,…,N, k = 1,..M. (2)
Будем характеризовать “квалификации” экспертов вероятностями P(Ai) ошибочной классификации, которые считаются известными для всех N экспертов на основании предыдущего опыта. При этом, естественно, допустить, что эти вероятности удовлетворяют условиям
P(Ai) < P0 для всех i = 1 ,…, N (3)
Ставится задача построения коллективного решающего правила, основанного на частных решениях экспертов, которое минимизирует среднюю вероятность ошибочной классификации.
Решающее правило 1.
Рассмотрим вначале простейший случай, когда число экспертов N=2 и число возможных классов M=2. В этом случае возможны четыре комбинации частных решений экспертов:
S11: δ1(Z) = 1, δ2(Z) = 1;
S12: δ1(Z) = 1, δ2(Z) = 2;
S21: δ1(Z) = 2, δ2(Z) = 1;
S22: δ1(Z) = 2, δ2(Z) = 2.
Как видно в ситуациях S12 и S21 решения экспертов противоречивы. Возникает естественный вопрос: какое решение следует принимать, чтобы минимизировать вероятность ошибочной классификации?
На первый взгляд может показаться, что в условиях противоречий следует принимать то решение, которое принял более “квалифицированный” эксперт. В то же время оказывается, что в общем случае такой подход неправомерен.
Для того, чтобы показать это, рассмотрим условные (апостериорные) вероятности P(V1/S12 ) и P(V2/S12 ) классов в ситуации S12. При этом для минимизации средней вероятности ошибочной классификации будем принимать окончательное решение в пользу класса V1, если
![]() P(V1 / S12 ) > P(V2 / S12 ) , (4)
P(V1 / S12 ) > P(V2 / S12 ) , (4)
и решение в пользу V2 в противном случае.
По формуле Байеса имеем
![]() ,
,
![]() .
.
Очевидно, что неравенство (4) имеет место в том и только в том случае , когда
P(V1)P(S12 / V1) > P(V2)P(S12 / V2) . (5)
По определению условная вероятность P(S12 / V1) есть ни что иное как вероятность того, что в ситуации, когда имеет место класс V1 , эксперт A2 принял правильное решение, а эксперт A1 ошибся. Поскольку мы предполагаем, что решения экспертов независимы, то по формуле произведения вероятностей
P(S12/V1) = [1-P(A1)]P(A2). (6)
Аналогичным образом
P(S12/V2 ) = P(A1)[1-P(A2)]. (7)
Неравенство (5) с учетом (6), (7), можно представить в виде:
P(V1)[1- P(A1) P(A2) > P(V2) P(A1) [1-P(A2)]. (8)
Из (8) вытекает, что в ситуации S12, когда решения экспертов противоречивы, объект Z следует относить к классу V1 в том и только том случае, когда
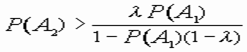 , (9)
, (9)
где λ = P(V2)/P(V1) – отношение априорных вероятностей классов.
Если же выполняется соотношение
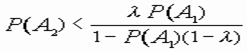 , (10)
, (10)
то в ситуации S12 объект Z следует относить к классу V2
Для иллюстрации на рис. 1 показаны границы областей решений, построенные для ситуации S12 согласно условиям (9), (10) при различных значениях λ. Область решения в пользу класса V1 расположена выше соответствующей границы, а решений в пользу класса V2 – ниже соответствующей границы.
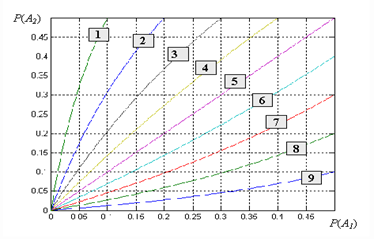
Рис. 1. Области решений для ситуации S12
1: λ = 9; 2: λ = 4; 3: λ =2.33; 4: λ =1.5; 5: λ = 1; 6: λ = 0.67;
7: λ = 0.43; 8: λ = 0.25; 9: λ = 0.11.
Аналогичным образом легко показать, что в ситуации S21 решение в пользу класса V1 следует принимать в том случае, когда
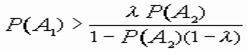 , (11)
, (11)
а решение в пользу класса V2, когда
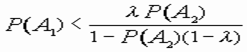 . (12)
. (12)
Заметим, что из (9)-(12) непосредственно следует, что только при равновероятных классах, когда λ =1, окончательное решение совпадает с решением того из экспертов, который имеет меньшую вероятность ошибки.
В остальных же случаях, когда λ ![]() 1, т.е.
1, т.е.![]() окончательное решение определяется не только соотношением вероятностей ошибок экспертов, но и соотношением априорных вероятностей классов. При этом окончательное решение может не совпадать с решением более “квалифицированного” эксперта.
окончательное решение определяется не только соотношением вероятностей ошибок экспертов, но и соотношением априорных вероятностей классов. При этом окончательное решение может не совпадать с решением более “квалифицированного” эксперта.
Поскольку примеры часто бывают более убедительными, чем формальные рассуждения, поясним сказанное на модельном примере.
Модельный пример.
Пусть P(V1)=0.3, P(V2)=0.7, а значит λ. = 2.33. Пусть далее известно, что первый эксперт ошибается в 5% случаев, т.е. P(A1)=0.05, а второй - в 8% случаев, т.е. P(A2)=0.08. Предположим, что эксперт A1 отнес объект к классу V1, а эксперт A2 - к классу V2, т.е. мы имеем ситуацию S12 противоречивых решений. Заметим, что первый эксперт более “квалифицированный”, так как P(A1) < P(A2).
Как видно из рис. 1 точка с координатами P(A1)=0.05 и P(A2)=0.08, расположена ниже границы, соответствующей λ. = 2.33. Следовательно объект должен быть отнесен к классу V2, хотя более квалифицированный эксперт A1 принял противоположное решение.
Для проверки обоснованности решения в пользу класса V2 определим по формуле Байеса апостериорные вероятности классов в рассматриваемой ситуации S12 :
![]() =
=![]() (13)
(13)
и
![]() =
=![]() . (14)
. (14)
Как видим P(V1/S12) < P(V2/S12), и значит объект действительно следует отнести к классу V2.
Изменим в условиях примера соотношения априорных вероятностей классов, положив P(V1) = 0.4, P(V2) = 0.6. В этом случае λ = 0.67 и, как видно из рис. 1, точка с координатами P(A1)=0.05 и P(A2)=0.08 попадает уже в область решений в пользу класса V1. В самом деле
![]() =
=![]()
и
![]() =
=![]() ,
,
т.е. P(V1/S12) > P(V2/S12). Значит в этом случае объект следует отнести к классу V2, что совпадает с решением более “квалифицированного” эксперта A1.
Итак мы показали, что при различных решениях двух независимых экспертов с фиксированными вероятностями ошибок окончательное решение изменяется с изменением λ.
Заметим, что рассматриваемая схема принятия решений основывается на знании весьма ограниченных вероятностных характеристик, которые при решении практических задач, в частности задач медицинской и технической диагностики, легко могут быть получены на основании предыдущего опыта. При достаточном числе наблюдений вероятности P(Vk) и P(Ai) могут быть оценены соответствующими частотами:
![]()
где Gk – общее число появлений k-го класса (k=1,2) в выборке из G наблюдений, а Ei – общее число ошибок i-го эксперта (i =1,2) в этой же выборке.
При этом совершенно не требуется знать, на основании какой информации эксперты принимают частные решения и как именно эксперты принимают эти решения – используя формальный или эвристический алгоритм, либо просто полагаясь на свою интуицию.
В то же время мы сделали одно важное допущение о том, что решения экспертов независимы, а вероятность ошибки каждого эксперта не зависит от класса, т.е. P(Ai)=P(Ai/V1)=P(Ai/V2). Естественно, что такое допущение должно быть обосновано.
Для того, чтобы продемонстрировать практическую возможность описанной схемы, рассмотрим один из возможных формальных алгоритмов принятия независимых решений двумя экспертами.
Предположим, что эксперт A1 классифицирует объект по бинарному признаку x1 (симптому), имеющему всего лишь две градации ![]() и
и ![]() , а эксперт A2 - по другому признаку x2, также имеющему две градации
, а эксперт A2 - по другому признаку x2, также имеющему две градации ![]() и
и ![]() . Будем считать, что для минимизации вероятности ошибок оба эксперта используют правило максимума апостериорных вероятностей, т. е. эксперт A1 принимает свое частное решение по максимуму P(V1/x1) и P(V1/x1), а эксперт A2 - по максимуму P(V1/x2) и P(V1/x2).
. Будем считать, что для минимизации вероятности ошибок оба эксперта используют правило максимума апостериорных вероятностей, т. е. эксперт A1 принимает свое частное решение по максимуму P(V1/x1) и P(V1/x1), а эксперт A2 - по максимуму P(V1/x2) и P(V1/x2).
Будем считать, что P(V1)=0.3, P(V2)=0.7, а также заданы условные распределения значений признаков в классах V1 и V2, которые представлены в таблицах 1 и 2 соответственно .
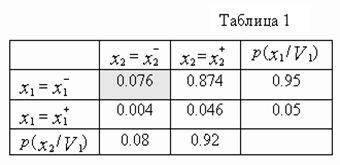
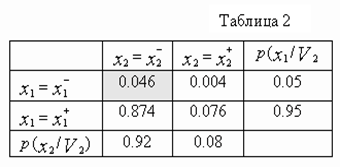
Для определения вероятности ошибочных решений эксперта A1 найдем апостериорные вероятности классов при возможных значениях признака x1:
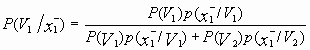 =
= ![]() ,
,
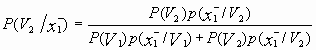 =
= ![]() ,
,
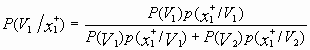 =
= ![]() ,
,
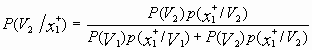 =
= ![]() .
.
Поскольку![]() и
и ![]() , то эксперт A1 классифицирует объект Z по признаку x1 следующим образом
, то эксперт A1 классифицирует объект Z по признаку x1 следующим образом
δ1(Z) = 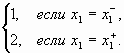 (15)
(15)
Легко видно, что ![]() , а значит вероятность ошибки первого эксперта не зависит от класса, т.е. P(A1)=P(A1/V1)=P(A1/V2) =0.05.
, а значит вероятность ошибки первого эксперта не зависит от класса, т.е. P(A1)=P(A1/V1)=P(A1/V2) =0.05.
Для определения вероятности ошибочных решений эксперта A2 найдем апостериорные вероятности классов при возможных значениях признака x2:
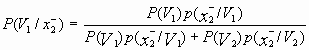 =
= ![]() ,
,
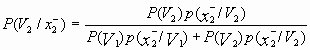 =
= ![]() ,
,
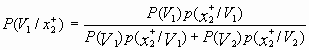 =
= ![]() ,
,
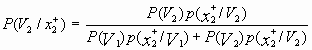 =
= ![]() .
.
Поскольку ![]() , а
, а ![]() , то эксперт A2 классифицирует объект Z по признаку x2 следующим образом
, то эксперт A2 классифицирует объект Z по признаку x2 следующим образом
δ2(Z) = 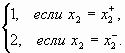 (16)
(16)
При этом вероятность ошибки эксперта A2 составляет P(A2)=0.08, причем эта вероятность также не зависит от класса, т.е. P(A2)= P(A2/V1) = P(A2/V2).
Как видно из таблиц 1 и 2 признаки x1 и x2 статистически независимы в обоих классах, поскольку для любых их значений справедливо соотношение p(x1,x2/Vk) = p(x1/Vk)p(x2/Vk) при k =1,2. Отсюда непосредственно следует, что решения (15),(16) экспертов будут независимыми.
Предположим, что в момент принятия решений признаки получили следующие значения ![]() , а
, а ![]() . В этом случае, согласно (15), (16), δ1(Z) = 1 и δ2(Z) = 2, т.е. требуется принять окончательное решение в условиях противоречивой ситуации S12. Поскольку априорные вероятности классов и найденные вероятности ошибок экспертов имеют такие же значения, как в первой части рассмотренного выше примера, то, согласно предложенной схеме, окончательное решение следует принимать в пользу V2.
. В этом случае, согласно (15), (16), δ1(Z) = 1 и δ2(Z) = 2, т.е. требуется принять окончательное решение в условиях противоречивой ситуации S12. Поскольку априорные вероятности классов и найденные вероятности ошибок экспертов имеют такие же значения, как в первой части рассмотренного выше примера, то, согласно предложенной схеме, окончательное решение следует принимать в пользу V2.
Покажем, что такое решение совпадает с оптимальным решением, основанным на результатах измерения совокупности двух признаков по формальному правилу максимуму апостериорных вероятностей классов![]() и
и ![]() . По формуле Байеса определим эти вероятности при
. По формуле Байеса определим эти вероятности при ![]() и
и ![]() :
:
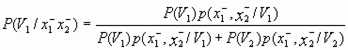 =
=![]() (17)
(17)
и
![]() =
=![]() . (18)
. (18)
Сравнение (13),(14) с (17),(18) позволяет заключить, что ![]() для k =1,2. Нетрудно убедиться в том, что аналогичные равенства имеют место и при других возможных значениях признаков.
для k =1,2. Нетрудно убедиться в том, что аналогичные равенства имеют место и при других возможных значениях признаков.
Следовательно, если эксперты принимают независимые решения, причем P(Ai/V1)=P(Ai/V2) при i =1, 2, то предлагаемая схема эквивалентна оптимальной, обеспечивающей минимум средней вероятности ошибочной классификации по совокупности двух независимых признаков в классах.
В условиях данного примера средняя вероятность ошибочных решений, принимаемых по результатам классификации двух экспертов, составляет 0.0406. Заметим, что эта величина меньше вероятности ошибки каждого из экспертов.
Решающее правило 2.
Предложенную схему легко можно обобщить на случай, когда вероятности ошибок экспертов зависят от классов. Такое обобщение актуально для решения практических задач, в частности, задач медицинской диагностики.
Пусть требуется отнести обследуемого пациента Z к одному из двух классов: V1 – болен, V2 – здоров. При этом будем считать известными априорные вероятности P(V1), P(V2), и ставить окончательный диагноз на основании информации, полученной от двух экспертов A1, A2, которые производят независимое обследование пациента по различным методикам.
Будем, как это принято в медицинской практике [23], оценивать “квалификацию” каждого из экспертов двумя величинами: чувствительностью Qi = 1- P(Ai /V1), где вероятность P(Ai /V1) ошибочного отнесения больного пациента к здоровому, и специфичностью Wi = 1- P(Ai /V2), где вероятность P(Ai /V2) ошибочного отнесения здорового пациента к больному (В теории распознавания вероятности P(Ai /V1) и P(Ai /V2) принято называть вероятностями ошибок первого и второго рода, или, что то же самое , вероятностями ошибок пропуска цели и ложной тревоги [24].).
Тогда в ситуации S12 , когда A1 признал Z больным, а A2 признал Z здоровым, окончательный диагноз следует ставить согласно схеме:
![]() (19)
(19)
где λ = P(V2)/P(V1) – отношение априорных вероятностей здоровых и больных пациентов.
Решающее правило 3.
Предположим теперь, что N >2 экспертов проводят независимое обследования пациента Z, в результате которых относят его к классу V1 (болен) или к классу V2 (здоров). Будем считать, что известны априорные вероятности P(V1) и P(V2), чувствительности Q1, …, QN и специфичности W1,…,WN каждого из экспертов.
Пусть в результате обследования получена комбинация S решений экспертов. Обозначим I1 - множество номеров экспертов, которые приняли решение в пользу класса V1, т.е. признали Z больным, а I2 - множество номеров экспертов, которые признали пациента здоровым. Очевидно, что I1 I2 = ; I1 I2 ={1,...,N}.
Тогда в ситуации S будем считать, что Z болен, если
![]() , (20)
, (20)
и Z здоров, если
![]() . (21)
. (21)
Решающее правило 4.
Рассмотрим теперь общий случай, когда требуется отнести объект Z к одному из M > 2 классов V1,..., VM. Будем полагать, что известны априорные вероятности классов P(V1),..., P(VM) и условные вероятности ошибочных решений P(A1/Vk),...,P(AN/Vk), (k=1,…,M), принимаемых N независимыми
10-09-2015, 22:43