В настоящее время в практику судебной медицины и криминалистики вошли новые методы идентификации, основанные на анализе дезоксирибонуклеиновой кислоты (ДНК). Информативность этих методов исключительно велика, так как высокий полиморфизм последовательностей ДНК делает ее неограниченным источником идентификационных признаков.
ДНК-анализ используется как в экспертизе вещественных доказательств, так и в экспертизе спорного происхождения детей.
Как и при классической дактилоскопии (исследовании папиллярных узоров), в ходе анализа ДНК не выявляются особые, свойственные только данному индивидууму, признаки. Каждый из изучаемых признаков обладает лишь групповой принадлежностью, однако в совокупности они позволяют индивидуализировать объект. Оценка идентификационного значения выявленных признаков осуществляется на основе вероятностных расчетов, базирующихся на данных о частотах встречаемости признаков у населения (в популяции). Частоты встречаемости признаков устанавливают опытным путем. Для этого исследуют определенную выборку людей, отражающую распределение признаков в популяции, и для каждого из них подсчитывают частоту встречаемости. Данные о частотах встречаемости позволяют вычислить вероятности идентификационных признаков. Вопросы, касающиеся расчета вероятности при оценке результатов ДНК-анализа, рассматриваются в ряде работ [1 - 14].
В вероятностных расчетах используют следующие обозначения и формулы.*
Основным идентификационным признаком является аллель. При популяционных исследованиях в пределах каждого локуса выявляется целый ряд аллелей; у отдельно взятого индивидуума при типировании локуса определяются один (го-мозиготная форма) или два (гетерозиготная форма) аллеля. Вероятность аллеля обозначается символом p. Символ pk означает вероятность того, что аллель принимает значение k. Например, символом p2 обозначается вероятность аллеля номер 2. Сумма вероятностей всех аллелей одного локуса в популяции равна 1, т.е. если в локусе n аллелей, то:
p1 + p2 +...... + pn = 1.
Вероятность встречаемости гетерозиготного профиля ДНК, состоящего из аллелей a и b (pa,b ), равна удвоенному произведению вероятностей соответствующих аллелей a и b:
pa,b = 2 pa pb при a ¹ b.
Вероятность встречаемости гомозиготного профиля ДНК, содержащего, например, аллель a (p a,a ), равна квадрату вероятности аллеля a: pa,a = p2 а .
Вероятность pа вычисляют на основании величины qa , обозначающей вероятность присутствия у индивидуума в типируемом локусе (хотя бы в одной из парных хромосом) аллеля a. Вероятность qa равна сумме всех генотипов, включающих в себя аллель a:
qa = p1,a +p2, а +... + pa, а +... + pn,a = 2p1 pa + 2p2 pa +... + p2 a +... + 2pn pa = pa (2 - pa ).
Откуда:
![]() .
.
Вероятность qa находят на основании данных популяционных исследований. Для этого подсчитывают qa (N) - частоту нахождения аллеля а в данном локусе ДНК, равную отношению числа проб (Nа ), в которых был выявле аллель а, к общему числу исследованных проб (N):
qа (N) = Na /N.
Если N велико, то, по закону больших чисел, частота qa (N) практически совпадает с вероятностью qa . Поэтому правомерно употребление понятий "частота" и "вероятность" почти как синонимов, так как они обозначают фактически одно и то же число.
В литературе для обозначения qa часто используется термин "частота встречаемости аллеля а в популяции". При всей традиционности этот термин, однако, является не совсем удачным, поскольку он может быть отнесен и к величине pa , которая меньше qa почти в 2 раза. Число рa есть вероятность нахождения аллеля а в одной хромосоме, а qa есть вероятность нахождения аллеля а хотя бы в одной из двух (парных) хромосом. Необходимо различать эти понятия.
Если генетический анализ проводится по нескольким локусам, наследование по которым происходит независимо, то вероятность комплекса признаков P равна произведению вероятностей каждого из них:
Р = Р1 Р2. .. Рn.
При идентификации искомой величиной является вероятность случайного совпадения признаков, выявленных в исследуемом объекте и сравниваемых с ним образцах. Вероятность случайного совпадения означает вероятность того, что тот же вывод был бы сделан, если бы профиль ДНК исследуемого объекта сравнивался с генотипом любого случайного индивидуума. Поскольку вероятность случайного совпадения воспринимается как абстрактное понятие, в выводах целесообразно выразить вычисленную величину через вероятность (частоту) встречаемости выявленного комплекса признаков. Возможна формулировка следующего вида: "Вероятность случайного совпадения выявленных генетических признаков составляет 2 10 -4, т. е. данные признаки в их совокупности могут быть обнаружены в среднем у двух человек из 10 тысяч".
Необходимо помнить, что слово "вероятность", так же как и теория вероятностей в целом, может относиться лишь к математической модели, а не к реальной жизненной ситуации. Поэтому в выводах не следует использовать формулировки типа: "Кровь в следах произошла от подозреваемого С. с вероятностью...", поскольку исследуемая кровь либо произошла от подозреваемого, либо нет.
Эксперт не компетентен в определении всех обстоятельств дела, это – задача следствия. Его обязанностью является предоставление объективной информации, основанной на данных исследования вещественных доказательств. Поэтому, формулируя вывод, эксперт не должен ни преувеличивать, ни преуменьшать значение выявленных им генетических признаков. Не следует, например, указывать, что данный признак может встретиться "лишь у одного человека из 10 тысяч". Много это или мало - в каждом случае вопрос неоднозначный и, как правило, находящийся вне компетенции эксперта.
Наибольшую сложность представляют случаи позитивной идентификации личности. Как оценить, достаточна ли полученная информация для того, чтобы сделать категорический вывод об источнике происхождения следов? Иными словами, при каком значении Р эксперт может утверждать, что исследуемый объект произошел именно от данного лица?
Для понимания этого вопроса рассмотрим следующую ситуацию. Установлено, что вероятность случайного совпадения профиля ДНК крови в следах с генотипом подозреваемого П. (под "генотипом" здесь и далее условно понимается та его часть, которая изучена в процессе исследования) составляет, например, 10-7 . При тех же объективных данных вывод о вероятности случайного совпадения признаков переформулируем, заменив его математически эквивалентным: какова вероятность того, что среди N потенциальных подозреваемых найдется хотя бы один, у которого генотип также будет согласовываться с профилем ДНК исследуемого объекта? Эта вероятность равна:
Q = 1 - (1-P)N = 1- e Nln(1-Р) ,
где e - основание натурального логарифма (e»2,718).
Если Р мало, то можно воспользоваться приближенной формулой ln(1 - P) = - P [точное неравенство - P ³ ln(1 - P) ³- P - Р2 , если P £ 0,5].
Пусть обстоятельства дела таковы, что число N потенциальных подозреваемых велико, например N = 5 106 (скажем, все взрослое население Москвы). Тогда Q» 1 - e- 0,5 » 0,39. По всей видимости, линия защиты при оценке такого экспертного заключения будет состоять в следующем: если с вероятностью 0,39 (т.е. 39%) среди N потенциальных подозреваемых найдется хотя бы еще один (кроме П.), генотип которого также согласуется с профилем ДНК исследуемого объекта, то, исходя из принципа презумпции невиновности, данные генетического анализа не могут быть положены в основу обвинительного заключения П. Это использовалось в зарубежной адвокатской практике для оправдания обвиняемого [9].
Приведенный пример показывает, что если вероятность случайного совпадения признаков в исследуемом объекте и генотипе проходящего по делу лица является малой величиной, это, тем не менее, не означает, что такие же признаки не могут присутствовать и в генотипе еще какого-нибудь индивидуума (и даже не одного). Так, в нашем примере такой индивидуум вполне вероятно мог встретиться в том же городе. Понятно, что если бы речь шла о населении не города, а, например,страны (или всего земного шара), то эта вероятность была бы еще большей. Напротив, когда круг подозреваемых строго ограничен (например, преступление совершено на корабле), эта вероятность мала. Так, если N = 1000, при том же значении Р = 10- 7 , что и в предыдущем примере, вероятность того, что в данной совокупности встретится хотя бы еще один индивидуум с такими же признаками, составит всего 0,0001, или 0,01%. (Если Р N £ 1, то можно пользоваться приближенной формулой Q = Р N.)
Заметим, что сама по себе возможность существования еще одного или даже нескольких индивидуумов с интересующими генетическими признаками (а она теоретически есть при любом значении вероятности Р) вовсе не лишает экспертизу доказательности. Ведь это не свидетельствует о том, что выводы эксперта относительно источника происхождения следов неверны. Это лишь показывает принципиальную возможность гипотетического существования индивидуума, характеризующегося аналогичным сочетанием аллелей. При этом речь идет о случайной выборке людей, включающей в том числе и тех, кто не мог быть участником данного преступления, например, в силу возраста, физического состояния и т. д. Значение имеет степень достоверности идентификации.
Для определения критерия достоверности идентификации мы предлагаем использовать следующий подход.
Если считать, что результаты экспертизы послужат основой обвинительного заключения по данному уголовному делу или решения суда о признании отцовства, то вероятность судебной ошибки (осуждения невиновного либо признания отцом человека, в действительности им не являющегося) равна вероятности случайного совпадения Р. Вероятность того, что ни одна из экспертиз, проведенных по N делам, не повлечет за собой судебной ошибки, равна (1-Р)N . Если Р N мало (скажем, Р N £ 0,2), то можно пользоваться приближенной формулой (1-Р)N » 1-Р N. Эта величина характеризует надежность метода идентификации по ДНК. Дальнейшие расчеты зависят от требований, предъявляемых к этой надежности. Если условием применения метода является требование, чтобы в течение 10 лет при его использовании не было допущено ни одной судебной ошибки, а число выполняемых в год идентификаций - порядка 1000, то получаются следующие выводы: если Р = 10- 5 , то вероятность того, что за десять лет не будет ни одной ошибки, равна 1 - Р N = 1-10- 5 104 = 0,9 = 90%; при Р = 10- 6 , Р = 10- 7 , Р = 10- 8 эта вероятность составит соответственно 99; 99,9; 99,99%. Последнее число очень велико и, видимо, достаточно для того, чтобы давать положительное заключение. Таким образом, при заданном значении N=104 величину 10- 8 можно принять за верхний предел вероятности случайного совпадения, при которой вывод правомерно формулировать в виде: "Следы крови произошли от К." или "С. является биологическим отцом ребенка А.". Данное значение Р с вероятностью 99,99% обеспечивает достоверность идентификации не менее чем в 10 000 случаев. При Р = 10- 9 достоверность идентификации с указанной вероятностью обеспечивается не менее чем в 100 000 случаев, и т.д.
Приведенные расчеты показывают возможный методический подход к интерпретации величины Р. Принципиально важным, однако, является вопрос о том, следует ли эксперту в своем заключении интерпретировать эту величину. Вопрос является спорным и требует специального рассмотрения.
Если обратиться к зарубежной практике, то известно, что во многих странах эксперт ограничивается лишь указанием значения Р, а оценивает эту величину суд, исходя из всех известных ему обстоятельств. Этот подход имеет особые основания для отечественной практики, принимая во внимание то, что популяционные исследования в России только начались и достаточной базы данных о генотипах еще не создано. В любом случае, ключевые проблемы позитивной идентификации должны решаться не отдельными специалистами, а широким кругом компетентных лиц, с обязательным участием юристов, на межведомственном уровне. По вопросу, следует ли эксперту в своем заключении интерпретировать величину Р, должно быть вынесено специальное решение.
Вероятностные расчеты при установлении тождества сравниваемых объектов
Задача состоит в следующем. Выявленный в исследуемом объекте Х (напри-мер, в пятне крови) профиль ДНК таков, что не исключена возможность того, что Х произошел от подозреваемого или потерпевшего (П). Требуется определить вероятность случайного совпадения профиля ДНК Х с генотипом П. Иными словами, необходимо установить, с какой вероятностью выявленные в объекте Х признаки совпали бы с генотипом случайно взятого индивидуума N.
Приведем несколько примеров.
Пример 1. При исследовании пятна выявляются два аллеля, совпадающие с гетерозиготным профилем ДНК подозреваемого П:
Х П.
а ______ _______
b ______ _______
В этом случае:
Р (профиль ДНК N равен а,b) = pa,b = 2 pа pb .
Пример 2. В объекте выявляется единичный аллель. Такой же аллель содержит и гомозиготный профиль ДНК подозреваемого П.:
Х П.
а _______ _______
В этом случае:
Р (профиль ДНК N равен а,а) =pa,a = p2 а.
Пример 3. В объекте обнаруживается более двух аллелей (а1 , а2 ,..., ак ). Это возможно, если Х, например, содержит кровь одновременно двух человек:
Х а1 _______ а2 _______ ............. _______ аk _______ |
П. _______ _______ |
Генотип П. согласуется с профилем ДНК Х, если П. имеет какие-то два аллеля аi и аj (при этом возможно, что i=j). Поэтому вероятность того, что генотип П. согласуется с Х случайно, равна:
![]() .
.
Окончательная формула расчета вероятности:
![]()
т. е. искомая величина Р равна квадрату суммы вероятностей всех выявленных в пятне аллелей.
По этой же формуле рассчитывается и вероятность Р в случае, когда в объекте выявляются только два аллеля а и b, но у эксперта есть основания полагать, что след оставлен не одним человеком, а двумя. Тогда:
Р = (pа + pb )2 = p2 а + p2 b + 2 pa pb.
Если таких оснований нет, то, как было указано, вероятность вычисляется по формуле:
Р = 2 pa pb.
Ситуации, когда исследуемый объект содержит как ДНК преступника, так и ДНК жертвы и неизвестно, за счет какого из этих генотипов выявляются аллели в профиле ДНК Х, требуют специального рассмотрения. Это часто имеет место в экспертизах, назначаемых по поводу преступлений, совершаемых по сексуальным мотивам.
Априори возможны следующие три гипотезы:
А1 = {профиль ДНК Х обусловлен генотипом преступника};
А2 = {профиль ДНК Х обусловлен генотипами преступника и жертвы};
A3 = {профиль ДНК Х обусловлен генотипом жертвы}.
Выводы о том, какая из этих гипотез справедлива, теория вероятностей сделать не позволяет. В некоторых случаях эксперт располагает данными, дающими ему основания предпочесть одну из гипотез двум другим или, по крайней мере, какую-либо из них исключить. Анализ ситуации базируется на оценке характера исследуемого объекта, а также на объективных данных, получаемых в процессе исследования. Например, при морфологическом исследовании пятна на одежде во всех полях зрения выявлено значительное количество сперматозоидов без примеси женских эпителиальных клеток.
Такой результат дает основания выбрать гипотезу А1 или, по крайней мере, хотя бы исключить гипотезу А3 .
Иная ситуация имеет место, например, при исследовании тампона с вагинальным содержимым жертвы. Такой объект исследования всегда изначально содержит ДНК потерпевшей, особенно если на тампоне имеется также и кровь. Если в препарате выявлены лишь единичные сперматозоиды, то такие данные, скорее всего, исключают гипотезу А1 , свидетельствуя в пользу гипотезы А2 , а в ряде случаев - гипотезы А3 . Оценка результатов упрощается, если проведена процедура "дифференциального лизиса".
Когда обстоятельства дела и данные, полученные в ходе исследования, не дают возможности выбрать какую-либо из гипотез А1 , А2 , А3 , то необходимо поступать следующим образом.
Так как при расчете вероятности нельзя занижать ее значение (это могло бы привести к осуждению невиновного человека), требуется вычислить каждую из вероятностей ![]()
![]() и затем в качестве окончательной оценки вероятности случайного совпадения выявленных аллелей с генотипом подозреваемого взять максимальную из них.
и затем в качестве окончательной оценки вероятности случайного совпадения выявленных аллелей с генотипом подозреваемого взять максимальную из них.
Так же следует поступать и при оценке двух гипотез, если исключена третья.
Пример 4. Аллельная характеристика объекта Х и генотипа П. совпадает. При этом один из выявленных аллелей соответствует также гомозиготному профилю ДНК жертвы (Ж):
Х П. Ж
а _______ _______
b _______ _______ _______
Такое расположение аллелей исключает гипотезу А3
. Вероятности ![]() равны:
равны:
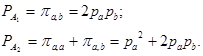
Так как наибольшей в этом случае является вероятность ![]() , то в качестве окончательного результата расчетов следует привести эту величину, указав, что
, то в качестве окончательного результата расчетов следует привести эту величину, указав, что ![]() .
.![]()
Пример 5. Профиль ДНК иследуемого объекта Х совпадает с генотипами подозреваемого и жертвы:
Х П. Ж
а _______ _______ _______
b _______ _______ _______
В этом случае априори не исключена ни одна из гипотез.
Соответствующие вероятности равны:
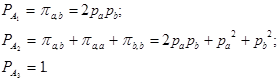
В случае, когда объективные данные, полученные в процессе исследования, дают хотя бы малейшее основание для того, чтобы допустить гипотезу А3 , следует отказаться от решения вопроса.
Если эксперт уверен, что характер исследованного материала исключает гипотезу А3 (например, наличие большого числа сперматозоидов при минимальном количестве или отсутствии эпителиальных клеток с Х-хроматином, делающее нереальным получение положительного результата с женской ДНК на фоне отрицательного результата с мужской ДНК), из двух оставшихся гипотез выбирают гипотезу А2 с соответствующим значением вероятности.
В случае, когда ДНК деградирована, не исключена возможность того, что один из аллелей локуса (скорее всего, более крупный) может не проамплифицироваться. Рассмотрим ситуацию, при которой допускается возможность выявления неполной аллельной характеристики исследуемого объекта.
Если профиль ДНК объекта Х представляет собой единичный аллель (обозначим его а) и из-за деградации ДНК мы не исключаем возможности того, что второй аллель просто не был обнаружен, возникают следующие две гипотезы:
В1 = {истинный профиль ДНК объекта Х есть (а,а)};
В2 = {второй аллель не обнаружен}.
Пример 6. В объекте выявлен единичный аллель, в крови подозреваемого (по-терпевшего) - два аллеля:
Х П.
b _______
a _______ _______
Ясно, что если в данном случае справедлива гипотеза В1
, то генотип подозреваемого не согласуется
8-09-2015, 19:44