Величина, що характеризує статистичний ефект. Аналіз результатів медико-біологічних досліджень
1. Основна мета клінічних досліджень. Методи порівняння з початковим станом.
Під час проведення клінічних досліджень зазвичай мають на меті 2 основні цілі: по-перше, оцінити дію пропонованого препарату (або лікування) на пацієнтів (або здорових добровольців), включених в дане дослідження, по-друге, більш загальна мета — на основі отриманих результатів передбачити майбутній можливий клінічний результат при впровадженні препарату (або методу лікування), що вивчається, в широку практику.
Іншими словами, основною формальною метою клінічних досліджень є оцінка ефекту (в широкому значенні слова) у групи осіб, що вивчається, для того, щоб можна було сказати, який лікувальний ефект можливий або швидше за все можливий з погляду теорії імовірності в майбутньому. Можна сказати, що вирішити першу задачу на практиці досить складно, тоді як другу – екстремально складно, якщо взагалі можливо.
Для того, щоб грамотно планувати клінічне дослідження, необхідно з найпершого етапу сформулювати його мету і спробувати зрозуміти, які саме показники можна використовувати для демонстрації і порівняння ефекту даного методу. Зазвичай один з таких показників вважається основним,
а інші — додатковими. З погляду математики і статистики, не існує принципової відмінності між ефектами, які медики відносять до прямої або побічної дії. Надалі ми не зупинятимемося на медичних визначеннях показників ефекту. Проте доцільно визначити поняття «ефект або ефект терапії, що в результаті вивчається», в контексті клінічних досліджень і математичної статистики. У загальному вигляді це визначення може звучати так: ефектом будь-якого лікування у конкретного пацієнта називається різниця між тим, що відбулося з даним пацієнтом в результаті проведення даного лікування, і тим, що могло б з ним відбутися у разі відмови від лікування даним методом. Зазвичай виникають деякі практичні труднощі при такому підході до визначення ефекту. Так, наприклад, одна з них була пов'язана з тим, що це визначення ефекту дано в термінах вибору. Друга – з тим, що, спостерігаючи за тим, що відбулося в результаті проведення даного лікування, неможливо спостерігати, що могло б відбутися. І, нарешті, третя — неможливо оцінити, що було б саме з цим пацієнтом, якби його лікували іншим методом. Таке порівняння можливо лише на основі вивчення паралельних груп або на основі історичного контролю, при цьому не тільки порівнювані методи лікування, але і самі пацієнти можуть розрізнятися, і не завжди всі відмінності можливо врахувати. Незважаючи на цю тонкість, з прийняття такого визначення відразу витікає ряд важливих практичних висновків.
Найважливішим висновком є те, що ефект визначається не просто як різниця між показниками пацієнта до і після проведення терапії, хоча у багатьох випадках ефект можна оцінювати саме так. Такий метод порівняння називається порівняння з початковим станом (baseline comparison). He у всіх випадках використання цього підходу приводить до бажаних результатів. Проілюструємо справедливість цього твердження на прикладах. Так, припустимо, що ми маємо справу з невиліковним захворюванням, яке припускає прогресивне погіршення стану пацієнта. Випробування нового препарату показало, що, наприклад, через 5 років його вживання різниця між початковими і результуючими показниками пацієнтів дорівнює нулю, тобто погіршення стану не відбулося, що саме по собі свідчить про наявність клінічного ефекту. Проте при такому виборі способу оцінки ефекту лікування формально ми отримаємо повну відсутність будь-якого ефекту від лікування даним препаратом.
Ще один цікавий приклад стосується оцінки ефекту. Уявіть собі, що в клінічних дослідженнях лікарського препарату беруть участь 10 осіб: 5 одержують препарат, що вивчається, а 5 — плацебо. В результаті проведення даної терапії передбачається збільшення значення якогось клінічного показника X, ця зміна і оцінюватиме ефект. Припустимо, в результаті випробувань були отримані такі значення змін показника X -0,2; -0,1; 0,0; 0,2; 0,5 для групи, що одержує активне лікування, і -0,5; -0,4; -0,3; -0,1; 0,2 у разі плацебо. Видно, що навіть не у всіх пацієнтів першої групи був досягнутий ефект щодо критерію даного дослідження. Проте можна помітити, що віднімання 0,3 із всіх значень показника в першій групі дає відповідне значення показника в другій (дані підібрані так спеціально для наочності). Отже на основі запропонованого нами загального визначення ефекту можна сказати, що кожен пацієнт першої групи в результаті проведення лікування одержує додаткове поліпшення даного параметра на 0,3 одиниці порівняно з відсутністю даної терапії (плацебо). Це ще одна ілюстрація того, наскільки важливо неформально ставитися до вибору параметрів для оцінки ефекту й аналізу отриманих результатів.
Інший, не менш показовий, приклад був пов'язаний з використанням методу регресії для демонстрації наявності ефекту від терапії, що проводиться. Припустимо, проводиться гіпотетичне неконтрольоване дослідження вигаданого препарату, скажімо, для нормалізації тиску систоли. Нехай початкова вибірка пацієнтів складається з пацієнтів як з підвищеним, так і зі зниженим тиском. Тиск систоли вимірюється кожному пацієнту двічі: до і після проведення терапії; після закінчення дослідження для всіх пацієнтів розраховується середній тиск до і середній тиск після. Різниця між цими величинами практично дорівнює нулю, оскільки вимірювання ДО підвищеного і зниженого тиску дали в середньому нормальне, а ПІСЛЯ — тиск нормалізувався в результаті терапії. Отже, якби таким чином оцінювали ефект терапії, він виявився б нульовим. Середнє арифметичне попарних різниць також дорівнювало б нулю. Використовувати в даному випадку кореляційний аналіз також даремно.
Умовна регресійна лінія проходить паралельно осі абсцис. Пряма Y=X є діагоналлю регресійної площини. По осі абсцис — вимірювання ДО; по осі ординат — вимірювання ПІСЛЯ.
Тепер спробуємо позначити на регресійній площині вимірювання наших пацієнтів у координатах тиск до — тиск після і проведемо пряму з початку координат Y=X. Можна помітити, що пацієнти, які мали початково низький тиск, підвищили його (відповідні точки на графіку лежать вище прямої Y= X), пацієнти ж з початково високим тиском його знизили (їх точки лежать нижче цієї прямої). Якби тиск у пацієнтів не змінювався в результаті терапії, на такому графіку точки розташовувалися б уздовж прямої Y=X.
У нашому випадку результат, що полягає в нормалізації тиску, на графіку подається у вигляді горизонтальної умовної регресійної лінії, побудованої за наявними даними і відповідно до нормальних значень тиску ПІСЛЯ. Таким чином, метод регресії, демонструючи варіацію даних, що вивчаються, водночас може дати наочне уявлення про наявність ефекту терапії в подібних ситуаціях. Проте не рекомендується у разі, коли незрозуміло, яку змінну вважати залежною, а яку — незалежною (випадок порівняння результатів вимірювання двома наближеними методами або випадок повторних вимірювань), розраховувати лінію регресії між такими змінними. Тут, точно кажучи, розташування результатів вимірювань на регресійній площині використовується тільки для демонстрації наявного ефекту.
Ще одна цікава задача виникає за необхідності порівняння результатів двох непрямих методів вимірювання або перевірки узгодженості повторних вимірювань, виконаних одним і тим самим методом. Оскільки в даному випадку неможливо прийняти якийсь метод вимірювання за еталонний, зазвичай для кожної зв'язаної пари вимірювань визначають її різницю. Систематична розбіжність результатів оцінюється за допомогою середньої різниці, як завжди, дисперсія різниці (або відповідне середнє квадратичне відхилення) – ступінь розкиду результатів. Зрозуміло, що якщо вимірювання дійсно узгоджені і систематичні розбіжності відсутні, середня різниця неістотно відрізнятиметься від нуля (з урахуванням розрахованої оцінки дисперсії). Стандартне відхилення різниці також не повинне бути дуже великим порівняно з самими значеннями. Крім того, не повинно бути вираженої залежності парних різниць вимірювань від величини вимірюваної ознаки. Коефіцієнт кореляції між вимірюваннями, виконаними різними способами, має бути близьким до 1. Це практично єдиний підхід до аналізу даних такого типу, який враховує відразу 3 статистичні характеристики: середнє значення, варіацію і кореляцію. Коефіцієнт кореляції між вимірюваннями, навіть якщо він приймає значення достатньо великі (за модулем близькі до 1), не може використовуватися як єдиний показник для аналізу даних такого типу. Регресійний аналіз у такій ситуації також незастосовний, оскільки невідомо, яку змінну вважати залежною, а яку — незалежною. Проте в регресійних координатах результати вимірювань мають розташовуватися уздовж прямого Y= X.
2. Статистичний аналіз результатів клінічних досліджень
Статистичний аналіз даних, отриманих під час клінічних досліджень, необхідний, оскільки відомо, що індивідуальна реакція пацієнтів (або здорових добровольців) може варіювати в достатньо широких межах. Разом з природним варіюванням на величині ознак позначаються і помилки вимірювань, і похибки в проведенні досліджень. Через це параметри, які кількісно оцінюють ефект, що вивчається, є випадковими величинами і мають бути описані відповідними статистичними характеристиками. Мовою математики окремі числові значення варіюючого параметра прийнято називати варіантами. Всі показники ефекту, що вивчаються, варіюються, але не всі вони піддаються безпосередньому вимірюванню. Так виникає розподіл на кількісні показники (які допускають безпосереднє вимірювання величини ефекту) і якісні (непіддатливі безпосередньому вимірюванню, наприклад, характеристики пацієнта: діагноз, стать, вроджені аномалії тощо). Якісні дані, які можуть бути віднесені тільки до двох протилежних категорій «так – ні», називаються дихотомічними (dichotomous data), з їх допомогою враховують показники ефекту в альтернативній формі (наприклад, визначення кількості або частини пацієнтів з числа випробовуваних, у яких спостерігався певний ефект). Якісні змінні можуть мати число градацій більше двох, їх зазвичай називають багатозначними якісними змінними. Кількісні дані можуть бути безперервними і дискретними. Безперервні дані можуть приймати будь-яке значення на безперервній шкалі, наприклад, маса тіла, температура, рівень глюкози в крові тощо. Дискретні дані можуть приймати лише певні значення з діапазону вимірювання, зазвичай цілі, наприклад число рецидивів за період, кількість перенесених операцій і т.ін. Виділяють ще один вид даних — порядкові дані. Можна сказати, що вони займають проміжне положення між кількісними і якісними типами даних. Їх можна упорядковувати як кількісні дані, але над ними не можна проводити арифметичні дії, як і над якісними даними. Прикладом таких даних може служити будь-який запитувач, що припускає, наприклад, оцінку стану пацієнта в термінах «дуже добре», «добре», «погано», «дуже погано». Треба попередити, що у багатьох випадках такий розподіл даних вельми умовний.
3. Нормальний розподіл показників і основні статистичні характеристики сукупності
У 1910 р. при вивченні розподілу декількох тисяч Американських солдатів за зростом вперше була знайдена цікава закономірність у розподілі цього показника. Ця особливість полягала в більш-менш симетричному накопиченні варіант у центрі ряду варіювання і поступовому зменшенні їх чисельності в міру віддалення від центру. Як з'ясувалося згодом, така закономірність властива розподілам багатьох показників, у тому числі і тих, що стосуються проявів клінічного ефекту. Це означає, що якщо на нескінченно великій кількості пацієнтів вимірюватиметься деякий показник ефекту, що викликається даним методом лікування, то графічне зображення результатів такого дослідження (вісь абсцис – величина ефекту, вісь ординат – кількість пацієнтів, у яких спостерігався ефект даної величини) часто описуватиметься симетричною кривою вигляду (рис. 2). Зображена на рис. 2 крива носить назву кривої нормального розподілу, або кривої Гаусса—Лапласа. В основному заради зручності обчислень у медицині часто робляться допущення про те, що той або інший клінічний показник був розподілений за нормальним законом.
Проте треба звернути увагу на те, що схожість реальних розподілів різних медичних показників з кривою нормального закону не є доведеною раз і назавжди, оскільки вона лише наближена. Остаточний висновок про конкретний закон розподілу даної сукупності робиться лише на підставі перевірки спеціальних статистичних тестів.
Крива нормального розподілу однозначно характеризується двома величинами: М — математичним очікуванням (або арифметичним середнім) і а — середнім квадратичним (або стандартним) відхиленням. Значення цих величин визначають положення кривої в системі координат та її форму. Так, максимум досягається в точці, відповідній середньому значенню М; середнє квадратичне відхилення визначає форму кривої: при великій варіабельності даних, тобто великому значенні а крива буде більш пологою, при малій — крутою. Таким чином, кількісний показник ефекту, розподілений за нормальним законом N (М, а), може бути охарактеризований середнім значенням М і середнім квадратичним відхиленням а (або дисперсією а2 ).
Значення середнього квадратичного відхилення у кожної представленої кривої більше, ніж у попередньої.
Дане твердження справедливе в припущенні про використання у дослідженні досить великої кількості пацієнтів або, кажучи математичною мовою, при суцільному вивченні генеральної сукупності. Проте в реальних умовах чисельність випробовуваних обмежена і являє вибірку з генеральної сукупності, а отже, точні значення М і а невідомі. Кількість об'єктів у вибірці (кількість пацієнтів у дослідженні) називається об'ємом вибірки і позначається n. При аналізі даних клінічних досліджень зазвичай доводиться мати справу з вибірками обмеженого об'єму. Відомо, що правильно відібрана частина генеральної сукупності досить добре відображає структуру цієї сукупності, але повного збігу вибіркових показників з характеристиками генеральної сукупності, як правило, не буває. Вибіркові характеристики є лише наближеними оцінками генеральних параметрів. Це — випадкові величини, і їх оцінки можуть бути точковими та інтервальними.
Вибіркове середнє X і вибіркове середнє квадратичне (або стандартне) відхилення Sx, є точковими оцінками відповідних параметрів М і а генеральної сукупності, і обчислюються за такими формулами:
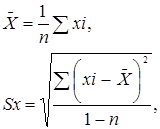
де ![]() —i-значення оцінюваної ознаки;
—i-значення оцінюваної ознаки;
n — об'єм вибірки;
![]() — знак підсумовування за всіма елементами вибірки (i = 1 ..., n).
— знак підсумовування за всіма елементами вибірки (i = 1 ..., n).
Dx = Sx2 — вибіркова дисперсія ознаки.
Величину відхилення вибіркового показника (статистики) від його генерального параметра називають статистичною помилкою. Для вимірювання цієї помилки деякої статистики служать дисперсія або квадратична (стандартна) помилка статистики (не можна плутати відповідно з вибірковими дисперсією і середнім квадратичним відхиленням випадкової змінної, що вивчається). Так, стандартна помилка середнього арифметичного х може бути знайдена за формулою:
![]()
За відомими точковими вибірковими характеристиками можна побудувати інтервальну оцінку або довірчий інтервал, в якому з тією або іншою імовірністю знаходиться генеральний параметр. Імовірності, що визнані достатніми для впевненої думки про генеральні параметри на підставі відомих вибіркових показників, називають довірчими. Зазвичай у медико-біологічних дослідженнях прийнятним є значення довірчої імовірності P = 0,95 (95%). При цьому імовірність виходу істинного значення параметра за ці межі не перевищує 1—0,95 = 0,05 (5%). Величину, яка доповнює довірчу вірогідність до одиниці, зазвичай позначають p.
Як відомо з центральної граничної теореми, незалежно від розподілу початкової сукупності, з якої були взяті вибірки, вибіркові середні мають приблизно нормальний розподіл. Таким чином, довірчий інтервал для вибіркового середнього значення знаходиться між X — tа
![]() х
і X +
tа
х
і X +
tа
![]() х
, де
х
, де ![]() х
— стандартна помилка середнього, tа
—
коефіцієнт Стьюдента, величина, залежна від об'єму вибірки n (або відповідного числа ступенів свободи) і вибраного рівня довірчої імовірності, визначається за таблицями розподілу Стьюдента. Величина коефіцієнта tа
визначається за таблицею на рівні p, що доповнює довірчу імовірність до 1, тобто у разі 95% довірчого інтервалу на рівні (P - 0,95) = 0,05 з урахуванням симетрії інтервалу.
х
— стандартна помилка середнього, tа
—
коефіцієнт Стьюдента, величина, залежна від об'єму вибірки n (або відповідного числа ступенів свободи) і вибраного рівня довірчої імовірності, визначається за таблицями розподілу Стьюдента. Величина коефіцієнта tа
визначається за таблицею на рівні p, що доповнює довірчу імовірність до 1, тобто у разі 95% довірчого інтервалу на рівні (P - 0,95) = 0,05 з урахуванням симетрії інтервалу.
У разі побудови довірчого інтервалу для вибіркового середнього значення число ступенів свободи при зверненні до таблиці Стьюдента обчислюється як n-1. У разі невідомої і оціненої за вибіркою дисперсії і при малому об'ємі вибірки для побудови довірчого інтервалу потрібно користуватися коефіцієнтом Стьюдента з урахуванням числа ступенів свободи.
При достатньо великому об'ємі вибірки (n > 30) виходить, що істинне середнє значення при рівні імовірності Р= 0,95 знаходиться в межах X ± 2![]() х
.
х
.
Як правило, під час аналізу результатів контрольованих клінічних досліджень середні значення обчислюються для порівняння їх з показниками групи контролю, на основі такого порівняння робляться певні висновки, заради яких і проводяться дослідження. Якщо дослідник просто порівнює середні значення, розраховані за малими вибірками, без урахування їх випадкової природи, виникає реальна небезпека помилкових висновків. Необхідно мати на увазі, що різниця середніх арифметичних двох вибірок, кожна з яких має свою помилку, також є випадковою величиною зі своєю стандартною помилкою. Порівняння вибіркових середніх арифметичних, розрахованих на основі обмеженої кількості спостережень, дозволяє оцінити лише довірчі границі, в межах яких при даному рівні значимості знаходиться різниця істинних середніх значень. Такі порівняння методами математичної статистики вимагають перевірки гіпотези про рівність середніх значень вибірок.
8-09-2015, 19:45