Содержание работы
Вступление
Теоретическая часть
Выявление различий в уровне исследуемого признака
Статистические гипотезы
Q – критерий Розенбаума
Практическая часть
Вывод
Список литературы
Вступление
Принято считать, что математика - это царица наук, и любая наука становится по-настоящему наукой, только когда она начинает использовать математику. Однако многие психологи в глубине души уверены, что царица наук - отнюдь не математика, а психология. Может быть, это скорее два независимых царства, существующих как параллельные миры?
Математику для доказательства своих положений совершенно не требуется привлекать психологию, а психологу можно совершать открытия, не привлекая математики. Большинство теорий личности и психотерапевтических концепций были сформулированы безо всякого обращения к математике.
Примером могут служить теория психоанализа, бихевиоральная концепция, аналитическая психология К. Юнга, индивидуальная психология А. Адлера, объективная психология В.М. Бехтерева, культурно-историческая теория Л.С. Выготского, концепция отношений личности В.Н. Мясищева и многие другие теории.
Но все это было, в основном, в прошлом. Многие психологические концепции ныне подвергаются сомнению на основании того, что они не были подтверждены статистически. Стало принято использовать математические методы. Но как не всякий молодой человек женится и не всякая девушка выходит замуж, так и не всякое психологическое исследование "венчается" с математикой.
"Брак" психологии с математикой - это брак по принуждению или недоразумению. "Глубокое внутреннее родство, общность происхождения современной физики и современной математики привели к опасному... представлению о том, что всякое явление обязано иметь математическую модель. Это представление тем опаснее, что оно часто считается само собой разумеющимся" (A.M.Молчанов).
Психология - это невеста без приданого, у которой нет ни своих собственных единиц измерения, ни отчетливого представления о том, как заимствованные ею единицы измерения - миллиметры, секунды и градусы - соотносятся с психическими феноменами. Эти единицы измерения она взяла напрокат у физики, как отчаявшаяся бедная невеста берет взаймы подвенечное платье у более обеспеченной подруги, лишь бы царственный старец взял ее себе в младшие жены.
Между тем, "...явления, составляющие предмет гуманитарных наук, неизмеримо сложнее тех, которыми занимаются точные. Они гораздо труднее (если вообще) поддаются формализации... Вербальный способ построения исследования здесь, как это ни парадоксально, оказывается точнее формально-логического" (И. Грекова).
Но каковы эти вербальные способы? Какой иной язык может предложить психология вместо уже ставшего привычным языка средних, стандартных отклонений, статистически значимых различий и факторных весов? Этой задачи психология пока не решила. Уникальная специфика психологического исследования пока все еще сводится к традиционному приписыванию рангов и чисел явлениям, столь тонким, неуловимым и динамичным, что, по-видимому, к ним применима лишь принципиально иная система регистрации и оценки. Психология отчасти сама виновата в том, что ее заставляют вступать в неравный брак с математикой. Она не смогла пока еще доказать, что строится на принципиально иных основах.
Но пока психология не докажет, что может существовать независимо от математики, развод невозможен. Нам придется применять математические методы, чтобы избавиться от необходимости объяснять, а почему мы, собственно, их не использовали? Легче использовать их, чем доказать, что в этом не было необходимости. Если же мы применяем их, то целесообразно извлечь из этого максимум пользы. В любом случае, математика, несомненно, систематизирует мышление и позволяет выявить закономерности, на первый взгляд не всегда очевидные.
Теоретическая часть
Выявление различий в уровне исследуемого признака
Обоснование задачи сопоставления и сравнения
Очень часто перед исследователем в психологии стоит задача выявления различий между двумя, тремя и более выборками испытуемых. Это может быть, например, задача определения психологических особенностей хронически больных детей по сравнению со здоровыми, юных правонарушителей по сравнению с законопослушными сверстниками или различий между работниками государственных предприятий и частных фирм, между людьми разной национальности или разной культуры и, наконец, между людьми разного возраста в методе "поперечных срезов".
Иногда по выявленным в исследовании статистически достоверным различиям формируется "групповой профиль" или "усредненный портрет" человека той или иной профессии, статуса, соматического заболевания и др.
В последние годы все чаще встает задача выявления психологического портрета специалиста новых профессий: "успешного менеджера", "успешного политика", "успешного торгового представителя", "успешного коммерческого директора" и др. Такого рода исследования не всегда подразумевают участие двух или более выборок. Иногда обследуется одна, но достаточно представительная выборка численностью не менее 60 человек, а затем внутри, этой выборки выделяются группы более и менее успешных специалистов, и их данные по исследованным переменным сопоставляются между собой. В самом простом случае критерием для разделения выборки на "успешных" и "неуспешных" будет средняя величина по показателю успешности. Однако такое деление является довольно грубым: лица, получившие близкие оценки по успешности, могут оказаться в противоположных группах, а лица, заметно различающиеся по оценкам успешности, - в одной и той же группе.
Это может исказить результаты сопоставления групп, или по крайней мере сделать различия между группами менее заметными.
Чтобы избежать этого, можно попробовать выделить группы "успешных" и "неуспешных" специалистов более строго, включая в первую из них только тех, чьи значения превышают среднюю величину не менее чем на 1/4 стандартного отклонения, а во вторую группу - только тех, чьи значения не менее чем на 1/4 стандартного отклонения ниже средней величины. При этом все, кто оказывается в зоне средних величин, М±1/46 , выпадают из дальнейших сопоставлений. Если распределение близко к нормальному, то выпадет примерно 19,8% испытуемых. Если распределение отличается от нормального, то таких испытуемых может быть и больше. Чтобы избежать потерь, можно сопоставлять не две, а три группы испытуемых: с высокой, средней и низкой профессиональной успешностью.
На Рис.1 представлена схема разделения выборки на группы с низкой, средней и высокой профессиональной успешностью по критерию отклонения значений от средней величины на 1/2 стандартного отклонения. При таком строгом критерии в "среднюю" группу попадают (при нормальном распределении) около 38,2% всех испытуемых, а в крайних группах оказывается по 30,9% испытуемых.
Чем меньше испытуемых оказывается в группах, тем меньше у нас возможностей для выявления достоверных различий, так как критические значения большинства критериев при малых n строже, чем при больших n.
Таким образом, при нестрогом разделении испытуемых на группы мы теряем в точности, а при строгом - в количестве испытуемых.
При решении задач выявления различий в уровневых показателях следует помнить, что "усредненный профиль успешного специалиста" должен рассматриваться скорее как исследовательский результат, позволяющий сформулировать гипотезы для дальнейших исследований, а не как основание для профессионального отбора. Тому есть две причины. Во-первых, ни у одного из успешных специалистов может не наблюдаться "усредненный профиль" - он, в сущности, является отвлеченным обобщением; во-вторых, в профессиональной деятельности наличие собственного индивидуального стиля важнее соответствия "среднегрупповому" профилю. Недостаток в тех качествах, которые могут казаться важными, компенсируется другими качествами. У каждого успешного специалиста его психологические свойства создают неповторимый ансамбль, который при усреднении данных теряется.
Р.Б. Кеттелл, учитывая это, предлагал при исследовании профессиональной успешности включать в рассмотрение индивидуальные профили выдающихся представителей той или иной профессии.
Сопоставление уровневых показателей в разных выборках может быть необходимой частью комплексных диагностических, учебных, психокоррекционных и иных программ. Оно помогает нам обратить внимание на те особенности обследованных выборок, которые должны быть учтены и использованы при адаптации программ к данной группе в процессе их конкретного воплощения.
Критерии, которые рассматриваются в данной работе, предполагают, что мы сопоставляем так называемые независимые выборки, то есть две или более выборки, состоящие из разных испытуемых. Тот испытуемый, который входит в одну выборку, уже не может входить в другую. В противоположность этому, если мы обследуем одну и ту же выборку испытуемых, несколько раз подвергая ее аналогичным измерениям ("замерам"), то перед нами - так называемые связанные, или зависимые, выборки данных.
Решение о выборе того или иного критерия принимается на основе того, сколько выборок сопоставляется и каков их объем.
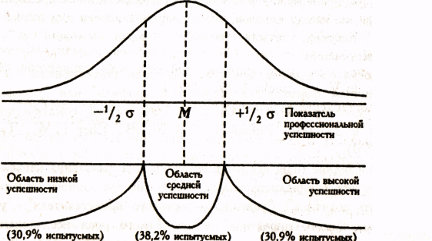 |
Рис. 1. Схематическое изображение процесса разделения выборки на группы с низкой, средней и высокой профессиональной успешностью
Статистические гипотезы
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил.
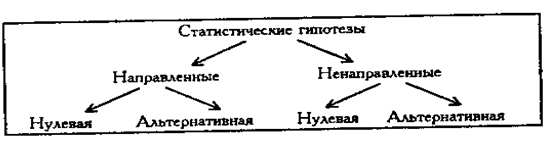
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.
Нулевая гипотеза - это гипотеза об отсутствии различий.
Она обозначается как H0 и называется нулевой потому, что содержит число 0: X1 —X2 =0, где X1 , Х2 - сопоставляемые значения признаков.
Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий..
Альтернативная гипотеза - это гипотеза о значимости различий. Она обозначается как H1 . Альтернативная гипотеза - это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы
H0 : X1 не превышает Х2
H1 : X1 превышает Х2
Ненаправленные гипотезы
H0 : X1 не отличается от Х2
Н1 : Х2 отличается от Х2
Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы.
При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить.
Построим схему - классификацию статистических гипотез.
 |
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
Q – критерий Розенбаума
Назначение критерия
Критерий используется для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. В каждой из выборок должно быть не менее 11 испытуемых.
Описание критерия
Это очень простой непараметрический критерий, который позволяет быстро оценить различия между двумя выборками по какому-либо признаку. Однако если критерий Q не выявляет достоверных различий, это еще не означает, что их действительно нет.
В этом случае стоит применить критерий ф* Фишера. Если же Q-критерий выявляет достоверные различия между выборками с уровнем значимости р <=0,01, можно ограничиться только им и избежать трудностей применения других критериев.
Критерий применяется в тех случаях, когда данные представлены по крайней мере в порядковой шкале. Признак должен варьировать в каком-то диапазоне значений, иначе сопоставления с помощью Q -критерия просто невозможны. Например, если у нас только 3 значения признака, 1, 2 и 3, - нам очень трудно будет установить различия. Метод Розенбаума требует, следовательно, достаточно тонко измеренных признаков.
Применение критерия начинаем с того, что упорядочиваем значения признака в обеих выборках по нарастанию (или убыванию) признака. Лучше всего, если данные каждого испытуемого представлены на отдельной карточке. Тогда ничего не стоит упорядочить два ряда значений по интересующему нас признаку, раскладывая карточки на столе. Так мы сразу увидим, совпадают ли диапазоны значений, и если нет, то насколько один ряд значений "выше" (S1 ), а второй - "ниже" (S2 ). Для того, чтобы не запутаться, в этом и во многих других критериях рекомендуется первым рядом (выборкой, группой) считать тот ряд, где значения выше, а вторым рядом - тот, где значения ниже.
Гипотезы
H0 : Уровень признака в выборке 1 не превышает уровня признака в выборке 2.
H1 : Уровень признака в выборке 1 превышает уровень признака в выборке 2.
Графическое представление критерия Q
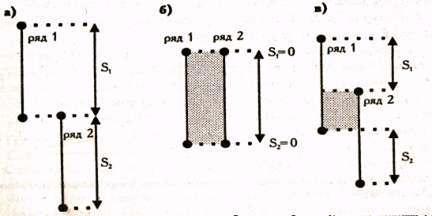
На Рис. 2. представлены три варианта соотношения рядов значений в двух выборках, В варианте (а) все значения первого ряда выше всех значений второго ряда. Различия, безусловно, достоверны, при соблюдении условия, что п1, п2 >=11.
В варианте (б), напротив, оба ряда находятся на одном и том же уровне: различия недостоверны. В варианте (в) ряды частично перекрещиваются, но все же первый ряд оказывается гораздо выше второго. Достаточно ли велики зоны S1 и S2 , в сумме составляющие Q, можно определить по Таблице I Приложения 1, где приведены критические значения Q для разных п. Чем величина Q больше, тем более достоверные различия мы сможем констатировать.
Рис. 2 Возможные соотношения рядов значений в двух выборках; S1 - зона значений 1-го ряда, которые выше максимального значения 2-го ряда; S2 - зона значении второго ряда, которые меньше минимального значения 1-го ряда; штриховкой отмечены перекрещивающиеся зоны двух рядов
 |
Ограничения критерия Q
1. В каждой из сопоставляемых выборок должно быть не менее 11 наблюдений. При этом объемы выборок должны примерно совпадать. Е.В. Гублером указываются следующие правила:
а) если в обеих выборках меньше 50 наблюдений, то абсолютная величина разности между n1 и n2 не должна быть больше 10 наблюдений;
б) если в каждой из выборок больше 51 наблюдения, но меньше 100, то абсолютная величина разности между п1 и n2 не должна быть больше 20 наблюдений;
в) если в каждой из выборок больше 100 наблюдений, то допускается, чтобы одна из выборок была больше другой не более чем в 1,5-2 раза (Гублер Е.В., 1978, с. 75).
2. Диапазоны разброса значений в двух выборках должны не совпадать между собой, в противном случае применение критерия бессмысленно. Между тем, возможны случаи, когда диапазоны разброса значений совпадают, но, вследствие разносторонней асимметрии двух распределений, различия в средних величинах признаков существенны (Рис. 3, 4).
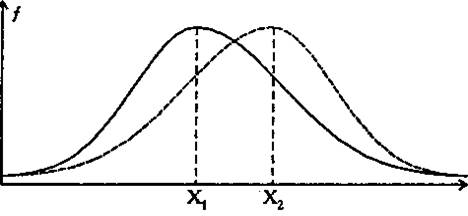
Рис. 3. Вариант соотношения распределении признака в двух выборках, при котором критерии Q беспомощен
 |
Рис. 4. Вариант соотношения распределении признака в двух выборках, при котором критерии Q может быть могущественным
Критические значения критерия Q Розенбаума для уровней статистической значимости р <=0,05 и р <=0,01 (по Гублеру Е.В., Генкину А.А., 1973)
Различия между двумя выборками можно считать достоверными (р <=0,05), если Qэмп равен или выше критического значения Q0,05 ,и тем более достоверными (р <=0,01), если Qэмп равен или выше критического значения Q0,01 .
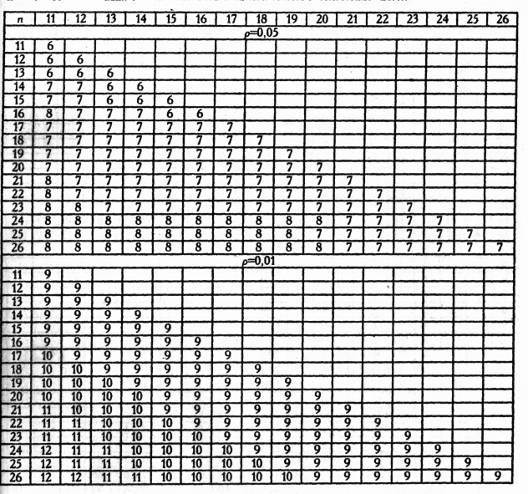 |
Таблица 1
Практическая часть
АЛГОРИТМ. Подсчет критерия Q Розенбаума
1. Проверить, выполняются ли ограничения: n1 ,n2 >=11, n1 = n2.
2. Упорядочить значения отдельно в каждой выборке по степени возрастания признака. Считать выборкой 1 ту выборку, значения в которой предположительно выше, а выборкой 2 - ту, где значения предположительно ниже.
3. Определить самое высокое (максимальное) значение в выборке 2.
4. Подсчитать количество значений в выборке 1, которые выше максимального значения в выборке 2. Обозначить полученную величину как S1 .
5. Определить самое низкое (минимальное) значение в выборке 1.
6. Подсчитать количество значений в выборке 2, которые ниже минимального значения выборки 1. Обозначить полученную величину как S2 .
7. Подсчитать эмпирическое значение Q по формуле: Q=S1 +S2
8. По Табл. 1. определить критические значения Q для данных n1 и n2 . Если Qэмп. равно Q0,05 или превышает его, H0 отвергается.
9. При n1 ,n2 >26 сопоставить полученное эмпирическое значение с QKp =8 (р <=0,05) и QKp =10(р <=0,01). Если Qэмп. превышает или по крайней мере равняется Qkp =8, H0 отвергается.
Ход работы.
У группы студентов был определен уровень эмпатии с помощью модифицированного опросника А.Меграбяна и Н.Эпштейна. Было опрошено 20 девушек и 16 юношей в возрасте от 20 до 23 лет. [3]
Результаты приведены в таблице 2 .
Таблица 2
| Девушки |
Юноши |
||||
| № пп |
Ф.И.О. |
Общий бал по свойству эмпатии |
№ пп |
Ф.И.О. |
Общий бал по свойству эмпатии |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
А.Е.В. А.С.К. В.Е.К. Г.А.Ф. Е.К.В. Е.А.А. З.Н.С. К.О.Р. К.О.Н. К.И.А. Л.Л.С. Н.О.М. Н.Ж.А. 9-09-2015, 20:01 Разделы сайта | ||||